CycleGAN
Last updated on a year ago
CycleGAN

📝 背景知識
- Generative Adversarial Networks
❗️ Introduction
成對的資料是非常難以搜集的(有點像監督式學習的方式,可以參考pix2pix),而CycleGAN只需要兩個domain的資料(例如一群馬的data與一群斑馬的data),就可以完成兩個domain內的互相轉換,這不僅降低了資料搜集的難度,也增廣了能應用的層面。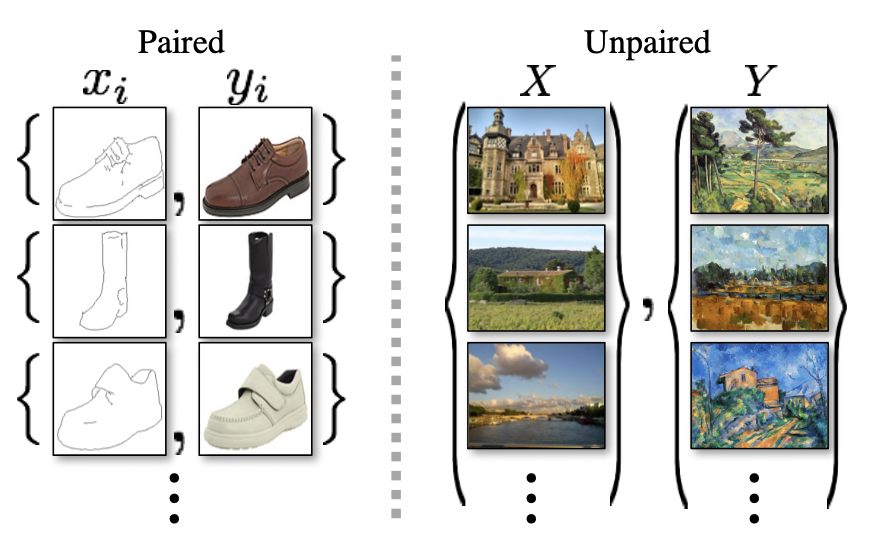
🏆 Goal
- Generator
- 我們以馬與斑馬作為例子,假設他們的資料及分別稱為$X$與$Y$,那我們要做的事情就是訓練兩個Generator$G$與$F$,我們希望 $X$經過 $G$後盡可能與$Y$越像越好,且$Y$經過$F$後也要可能與$X$越像越好。寫成數學一點就是$G(x)\approx y$,且$F(y)\approx x$ ($x \in X$ and $y \in Y$)。
- Discriminator
- 要如何衡量生成器的好壞,就輪到我們的Discriminator出場啦,我們一樣有兩個Discrminator $D_X$與$D_Y$,分別是判斷$F(y)$與$x$是否足夠相似與$G(x)$與$y$是否足夠相似,其實就有點像是在train一個classifier的感覺,因此整體的架構如下:
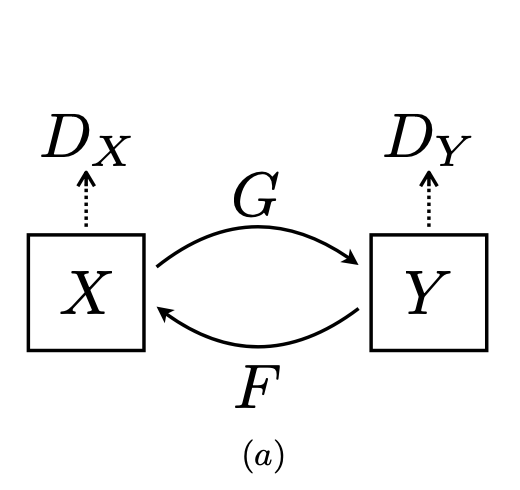
- Loss Function
- Adversarial Loss
- $\mathcal{L}_{GAN}(G, D_Y, X, Y) = \mathbb{E} _{p \sim data(y)}[\log (D_Y(y))] + \mathbb{E} _{p \sim data(x)}[\log (1 - D_Y(G(x)))] $
- 我們以$G$(使x mapping to y)與$D_Y$(分辨$G(x)$與$y$)作為例子,這個loss的主要功用就是讓最的$G(x)$與$y$越像好,對於Generator來說,我們會希望去minimize這個loss,而Discrminator則是相反,希望去maximize這個loss,對於$F$與$D_X$也是一樣的。
- Cycle Consistency Loss
- $\mathcal{L}_{cyc}(G, F) = \mathbb{E} _{p \sim data(x)}[||F(G(x)) - x||_1] + \mathbb{E} _{p \sim data(y)}[||G(F(y)) - y||_1]$
- 單單只有Adversarial Loss是無法讓整個model有好效果的,因為我們無法確定$x$與$G(x)$是否足夠類似,因此我們需要利用來回映射(以馬為例子就是:馬➡️斑馬➡️馬),也就是希望讓$x$與$F(G(x))$越像越好。
作者在論文中有提到,相較起來L1的效果是最好的
- Identity Loss(optional)
- $\mathcal{L}_{identity}(G, F) = \mathbb{E} _{p \sim data(y)}[||G(y) - y||_1] + \mathbb{E} _{p \sim data(x)}[||F(x) - x||_1]$
- 這個loss作者只簡單地提及了一下,但它也是一個非常重要的loss。我們知道$G$是用來生成斑馬的Generator,因此若我們將斑馬$y$丟進這個Generator後,出來的結果也應該是斑馬,因此這個loss就是在最小化這件事。
當初我在報這篇論文給教授聽時報告錯這個部分,真尷尬:)
- Adversarial Loss
🍎 Result

CycleGAN
http://example.com/2022/08/23/20220823/